What is a Bε-tree?
A Bε-tree is a B-tree, augmented with per-node buffers. New items are inserted in the buffer of the root node of a Bε-tree. When a node’s buffer becomes full, messages are moved from that node’s buffer to one of its children’s buffers. The leaves of the Bε-tree store key-value pairs, as in a B-tree. Point and range queries behave similarly to a B-tree, except that each buffer on the path from root to leaf must also be checked for items that affect the query.What are the key performance optimizations of a Bε-tree?
Several features give Bε-trees and BetrFS a performance edge. Some of the most significant:
- Upserts. An upsert encodes an asynchronous update operation on a key in the WOI. Upserts can include conditional logic and operate at arbitrary granularity, including sub block updates. The main caveat is, for an upsert to realize optimal performance, the caller cannot wait on the result of an upsert. When the kernel can calculate the result of an upsert from cache, or need not wait for the result, an upsert can convert read-modify-write patterns in to more efficient blind writes.
- Large leaves (2-4 MB). Aggregating multiple small writes into a single, large write significantly reduces the seeks per write and read. Because upserts can handle sub-block cases, leaves need not be read into memory until a significant number of updates are pending (or the system is idle). Moreover, in the case of sequential reads, seek costs are minimal.
- Blind Writes. One essential performance insight in dealing with WOIs is that writes are faster than reads. So whenever a read can be avoided in favor of a blind write, the system will perform better.
- Lexicographic ordering on disk.BetrFS orders data and metadata by full path, preserving locality for sequential reads and searches.
Why use a Bε-tree instead of an LSM tree?
LSM trees can be tuned to have the same insertion complexity as a Bε-tree, but queries in a natıvely implemented LSM tree can be slow, as shown in the table below. Bloom filters can improve point query performance of an LSM tree, but not range query performance.

Bε-trees are the only WOI implementation that matches the query performance of B-trees for all workloads. In short, LSMs match B-tree query times in special cases, and Bε-trees match B-tree query times in general.
What sort of applications perform well on BetrFS?
Any workloads that do small, random, blind writes (i.e., writes without a preceding read) will particularly benefit on BetrFS. BetrFS is also good for sequential scans and searches within the file system. In many cases, the performance is comparable either way.
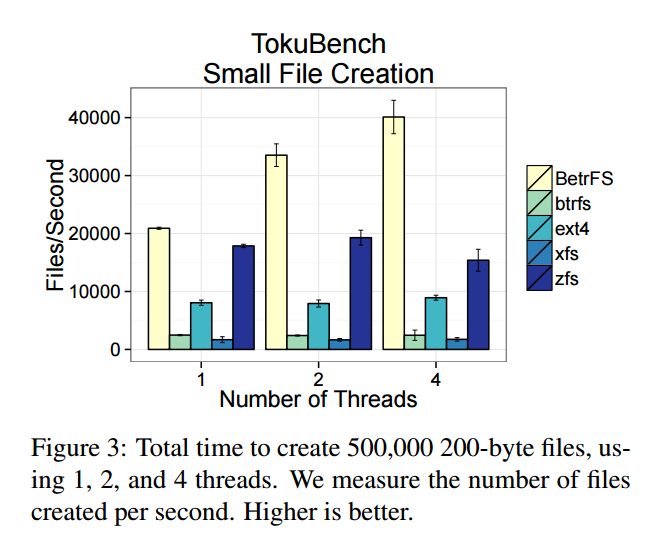
These graphs illustrate both random writes within a large file and small file creation within a directory on several general-purpose file systems:

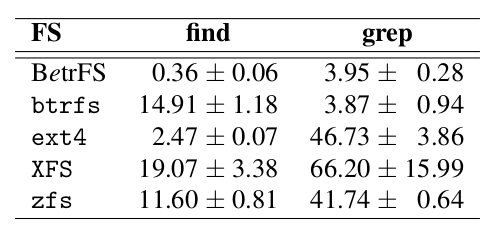
In the case of scans, such as grep and find, BetrFS also does quite well:
Our goal is that no application should perform worse, but more research is needed for several cases.
What are the current worst cases for BetrFS?
BetrFS currently performs worse than other file systems on three types of operations, which we plan to address in the future:Large, sequential I/O. In the case of writes, this is the cost of essentially full data journaling (and possibly logarithmic extra writes), compared to less aggressive schemes.
Large file deletes and trucates. These overheads are attributable to the sheer number of deletion upserts that must be inserted for a delete.
Large directory renames. BetrFS organizes data lexicographically on disk, which ensures locality, but requires copying data during renames. This currently trades search performance for rename time. We believe the costs of rename can be reduced.
Why is BetrFS a stacked file system?
As an implementation convenience, we use ext4 as a block allocator underneath our B^e tree implementation. We intend to streamline this layer in future releases.
What support do you require from the kernel?
Our design minimizes changes to the kernel. The current code requires a few kernel patches, such as enabling direct I/O from one file system to another. We expect to eliminate most of these patches in future versions.
What devices did you design BetrFS for?
We have currently been measuring and tuning performance on traditional hard drives (HDDs), although the code should also work on solid state drives (SSDs). Stay tuned for measurements of SSD performance.